About a year ago, I co-wrote a blog with Sean O’Dell of Disney that envisioned the “Continuous Security Paradigm”. It proposes an architecture wherein independent services asynchronously exchange data that is relevant to making access decisions. Such asynchronous exchange of data provides the up-to-date context that is essential to good access decisions.
In this blog, I’m breaking down why it’s important to have the CSP as the modern security model. As I’ve written before, the shared responsibility model has the consequence that most of the security controls organizations have are about access. As a result, the CSP focuses on how organizations can make access decisions in the modern, cloud-based environments.
Network of nodes
Modern organizations typically use a number of cloud services, including SaaS, PaaS, and IaaS services. Your IaaS platforms host multiple systems and applications. Each one of these services (including your own systems and applications) can be thought of as a node in a network. Each node has relative autonomy in its operation, and has management concerns of its own, but as an enterprise, you want it to work and be managed in coordination with other systems that you run.
Zero trust
Your users are located everywhere on the globe, and work from their individual homes, on the road, or in offices, and need to access cloud-based services. These services are themselves globally distributed, therefore it is natural to have users connect directly to such cloud services without going through any specific network hops. A zero trust architecture - one in which every access is verified independently directly by the service being accessed - is the natural choice to enforce access security in such environments. This is because any network security architecture places unnecessary hops and as a consequence, points of failure. Network components also cannot incorporate any context in an access decision, so their decisions are necessarily based on static role memberships and network properties. As a result, providing network constraints on access can only enforce access by static data or environmental factors (e.g. IP address location), but cannot enforce access based on current context.
Access tokens
In a zero-trust architecture, access is enforced at every resource request, based on information that is verified at the time of access. In real life, this often means verifying the access token that gives the user the ability to access a specific service. Access tokens are issued by a combination of your organization’s identity provider, and the specific system a user is trying to access. The IdP issues tokens using federated identity protocols such as OpenID Connect (OIDC) or SAML, the individual systems may use proprietary or JWT format OAuth access tokens for their individual use. These access tokens are either stored as cookies in browsers or as access tokens in mobile apps.
The access tokens have a validity lifetime of their own, determined by your organization by configuring the individual system that issues the tokens. Security practitioners have to decide whether the access token should be long-lived (e.g. 24 hours), or short lived (e.g. minutes to an hour). This is typically determined by how often a user’s access posture is likely to change. Keeping a short token lifetime forces the user to have to go back to the IdP to re-issue the federated identity token, which is disruptive to the user’s experience and can place an unacceptably high burden on the IdP.
Therein lies the dilemma of the security practitioner: If you make token lifetimes too long, security suffers, and if you reduce token lifetimes, the user experience and system reliability suffers.
Access decisions
Ideally, In a zero-trust architecture, access decisions should be made independently for every access. Instead systems use token validity as a quick means of verifying access, because that seems like a good way to do a low-latency check that doesn’t require a lot of complex computation that might go into an access decision. But let’s take a look at how it should really work:
Context is distributed
Each node has your organization’s data, and data from any node could be required to make access decisions at any other node. When a user (or an API call) makes a request to a specific node, it needs a near-instantaneous access decision. However, the data required to deliver that access decision may be drawn from other nodes. Expecting all such nodes to work synchronously in real-time to provide an access decision with ultra-low latency is virtually impossible.
Consider the following examples:
Consumer use case:
A customer of a bank has logged in and is requesting to transfer money from one of their accounts. The application responsible for executing the transfer needs data from the fraud alerting system to know whether the user’s login session is showing any signs of compromise, such as session hijacking or credentials compromise. An independent fraud detection system can compute this information, but it needs access to other systems such as the identity provider, geolocation, etc. to do such computation. So, when the transfer execution system is invoked in order to execute the transfer, it is unrealistic to expect it to reach out to the fraud detection system, and then have that reach out to the IdP and geolocation services to compute all this in real-time. It also doesn’t work because each system may have differing availability and latency characteristics.
Enterprise use case:
An employee wishes to make a change in the configuration of your organization’s IaaS platform. This is a highly sensitive change, so your organization has decided that this should be allowed only if…
Real-time conditions
- There is a support case that is approved for configuration changes in production
- The user is assigned as the engineer on that case
- The user is currently on duty as an on-call engineer
- The user is in the “site reliability engineering” team that is permitted to make such changes
- The user is not on leave at this time
- The user is coming from a PC that does not have any incidents reported, and is in good management posture
All of these pieces of data are in different systems (e.g. ticketing system, on-call scheduling system, enterprise directory, HR, XDR, etc.). All of this data influences the access decision. It is unimaginable that all this information is retrieved and an access decision is made at the time the user is trying to access the IaaS system.
Achieving continuous security
So, is it even possible for one to achieve continuous security as described above in a reliable, low-latency way? Keep in mind that in large organizations, individual systems may have hundreds of thousands of access requests every second.
So, while it is impossible to rely on all this distributed data to make such highly reliable, low-latency access decisions, that doesn’t mean continuous security is impossible to achieve.
The continuous security paradigm makes this possible. The idea is actually quite simple:
- Always make instantaneous access decisions based on data available at the individual node. In its simplest form, this can be validating an access token
- Ensure that data required for making access decisions at any node is available as soon as it changes, regardless of which node that data originates from. This can be achieved using asynchronous communication of such changes.
- If data you have changes, you need to ensure it is communicated to the nodes that need it in order to make decisions.
If you are simply relying on access tokens, you need to make sure that nodes that rely on the validity of the access token know in advance if the access token should be considered invalid due to changes in other systems (e.g. a user being terminated). That way, when a user shows up with that token, it is immediately discarded and access is denied.
At a glance: the continuous security paradigm
The continuous security paradigm embodies the principles above, as seen in the diagram below:
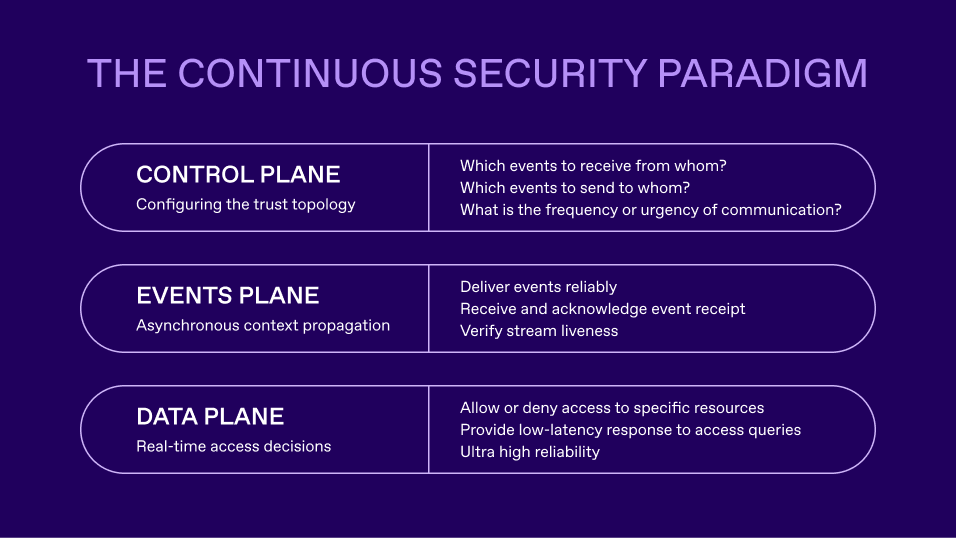
To learn more about the Continuous Security Paradigm, read the original blog: The Continuous Security Paradigm
CSP, Continuous Identity, and SGNL
Continuous Identity is the practical embodiment of CSP that delivers contextually-informed policies, consistently applied throughout the identity and security infrastructure, and continually enforced which helps organizations deliver zero standing privileges and just-in-time access.
SGNL implements CSP, either using standards such as CAEP where they are supported, or using proprietary integrations where necessary.
SGNL provides highly reliable, ultra-low latency access decisions based on data that is asynchronously ingested from systems of record, which are other nodes in your network. You can employ SGNL based access decisions in any node in your network, because SGNL propagates the necessary changes asynchronously to the nodes in order for them to make access decisions based on updated data.
For example, to implement the “Enterprise use case” above, SGNL integrates with all the systems described to obtain data asynchronously from them. At the time the access decision is needed, all information to make that decision is already in the local node. To effect the access decision at remote nodes, SGNL pushes asynchronous updates to security roles within the target systems (e.g. IaaS) so that when the user tries to access using an existing access token, they are still unable to perform any task, because the local role membership data at that node has been updated to remove membership of any roles that would permit such tasks.
